Guides • 14 min
OpenClaw vs. Hermes Agent: Same Loop, Different Bets
A side-by-side guide to how two agents can share the same loop while making very different harness decisions.
The recent proliferation of AI coding agents has inspired a heated debate among developers about whether they're anything more than "just wrappers" around language model calls. It is true that at their most basic, agents perform a generalizable sequence of actions based around sending and receiving messages, calling and executing tools, and repeating this loop until a certain success criterion is met.
But once the loop is commoditized, the design decisions around the wrapper become the differentiating product. Agents can share the same call shape while making opposing bets about what to remember, automate, and allow. Variations in context assembly, task orchestration, execution policy, and durable state combine to produce widely disparate behaviors and outcomes.
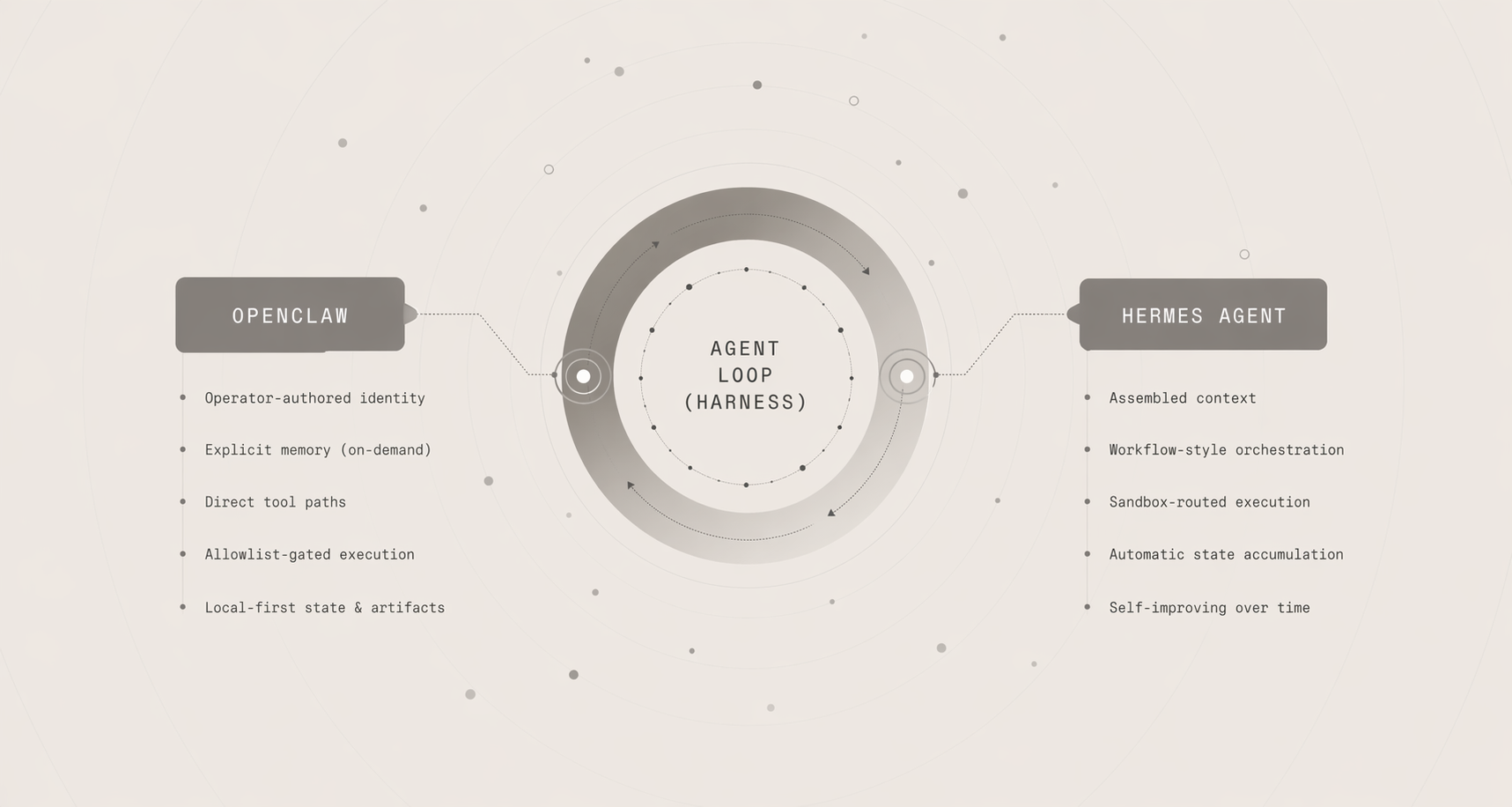
This article compares OpenClaw and Hermes Agent through a companion repo that holds the loop constant so the harness choices become visible and inspectable.
- OpenClaw is a local-first assistant with operator-authored identity, explicit memory, direct tool paths, and allowlist-gated execution.
- Hermes is a self-improving agent with assembled context, workflow-style orchestration, sandbox-routed execution, and automatic state accumulation.
This article examines four primary categories of comparison that foreground contrasting decisions and priorities around architecture and product design:
- Context and Memory
- Task Orchestration
- Execution and Confinement
- State and Artifacts
Following Along
The companion repo is located at github.com/ajcwebdev/system-and-signal. Clone it, install dependencies, and create a .env file using .env.example:
git clone https://github.com/ajcwebdev/system-and-signal.git
cd system-and-signal
bun install
cp .env.example .envSet your OpenAI key to OPENAI_API_KEY in .env:
OPENAI_API_KEY=...The CLI includes four main flags, each with a one letter alias:
-pfor--profile-ufor--user-sfor--session-mfor--message
To see changes between the two agents, swap the input to --profile between openclaw and hermes and compare results. There are three parts of the output that are most important to focus on:
- System Prompt Sections: What the harness assembled before the model answered.
- Model Decisions: What kind of tool path the model took.
- Side effects:
Memory Writes,User Model Updates,Generated Skills,Permission Decisions, andSandbox Events.
The CLI logs the output result for each harness design.
Context and Memory
Our first comparison highlights one of the core distinctions between OpenClaw and Hermes. What state do they each assemble before the model begins its turn?
Start on a fresh run by asking OpenClaw a question about one of its preferences such as what shell it prefers:
bun ah -p openclaw -m "What shell do I prefer?"OpenClaw replies that it doesn't have that information stored yet:
Reply: I do not have that stored yet.
System Prompt Sections
> Loaded operator-authored SOUL.md identity.
> Memory stays passive unless the user explicitly saves or searches it.
> Command permissions use a fixed allowlist and return needs_approval otherwise.
Model Decisions
? No proactive preference in context dispatching search_memory.
? Tool results detected (search_memory) composing final response.The key line here is Memory stays passive unless the user explicitly saves or searches it.. This means memory does exist but it isn't automatically injected because OpenClaw must be explicitly told to remember something such as preferring zsh for shell work:
bun ah -p openclaw -u alice -s prefs -m "Remember that I prefer zsh for shell work"This time there's an explicit memory update:
Reply: Saved explicit memory: I prefer zsh for shell work.
Memory Writes
+ Saved explicit memory: I prefer zsh for shell work
Model Decisions
? Dispatching save_memory for "I prefer zsh for shell work".
? Tool results detected (save_memory) composing final response.Since we triggered saving a memory, OpenClaw will now correctly recall the saved information:
bun ah -p openclaw -u alice -s prefs -m "What shell do I prefer?"This time it will know what shell is preferred:
Reply: Here is the strongest match I found in memory: I prefer zsh for shell work.
Model Decisions
? No proactive preference in context dispatching search_memory.
? Tool results detected (search_memory) composing final response.There is no silent or background learning and no hidden carry-forward state.
Now ask Hermes the same question on a fresh run:
bun ah -p hermes -m "What shell do I prefer?"Whereas OpenClaw loaded an identity doc and nothing else, Hermes injects curated memory, a learned user model, generated skills, and recent session recall before the model sees the turn:
Reply: Here is the strongest match I found in memory: The demo project is a Bun companion implementation for the article.
System Prompt Sections
> Injected curated memory from MEMORY.md.
> Injected learned user model from USER.md.
> Injected generated skills and recent session recall.
> Automatic post-turn learning can update the user model and create skill notes.
Model Decisions
? No proactive preference in context dispatching search_memory.
? Tool results detected (search_memory) composing final response.We don't need to directly instruct the agent to remember something, we can simply state our preference.
bun ah -p hermes -u alice -s prefs -m "I prefer zsh for shell work"And Hermes automatically updates its user model accordingly:
Reply: This hermes demo is using the shared agent loop. I did not need any tools for: "I prefer zsh for shell work"
Recalled Entries
~ session:logs:user: search recent logs for timeout failures
User Model Updates
+ User prefers zsh for shell work.
Model Decisions
? No tool call required returning direct response.Now ask the question again:
bun ah -p hermes -u alice -s prefs -m "What shell do I prefer?"We can see that Hermes has automatically learned during the turn itself without needing to be explicitly told:
Reply: You prefer zsh for shell work.
Recalled Entries
~ session:prefs:user: I prefer zsh for shell work
~ session:prefs:assistant: This hermes demo is using the shared agent loop. I did not need any tools for: "I prefer zsh for shell work"
Model Decisions
? Answering from assembled context with stored preference "zsh for shell work".Task Orchestration
Next, we'll examine how each harness decomposes work after the request arrives.
bun ah -p openclaw -u alice -s logs -m "search recent logs for timeout failures"OpenClaw makes one request with one tool and gives one answer containing the direct paths that satisfy the search query:
Reply: I checked the demo log for "timeout failures".
Found 2 matching log lines.
demo.log:2: 2026-03-14T18:03:44Z ERROR request failed: timeout while contacting model gateway
demo.log:3: 2026-03-14T18:05:15Z ERROR worker crashed after repeated timeout failures
Model Decisions
? Dispatching search_logs for "timeout failures".
? Tool results detected (search_logs) composing final response.Here's the same request through Hermes:
bun ah -p hermes -u alice -s logs -m "search recent logs for timeout failures"In contrast, Hermes stages a workflow that utilizes a script-like task, report artifact, sandboxed workspace, and a reusable skill:
Reply: Executed Hermes script: analyze timeout failures
Report: reports/timeout-failures.txt
Matches: 2
data/logs/demo.log:2: 2026-03-14T18:03:44Z ERROR request failed: timeout while contacting model gateway
data/logs/demo.log:3: 2026-03-14T18:05:15Z ERROR worker crashed after repeated timeout failures
Generated Skills
* ./data/skills/search-recent-logs-for-timeout-failures.md
Sandbox Events
# Synced Hermes sandbox fixtures into ./data/sandboxes/hermes.
# Wrote sandbox report ./data/sandboxes/hermes/reports/timeout-failures.txt.
Model Decisions
? Dispatching execute_code for "timeout failures".
? Tool results detected (execute_code) composing final response.Execution and Confinement
Another crucial decision for agents concerns what a tool is allowed to read or write, where it is allowed to do so, and what policy decides these permissions.
Ask OpenClaw to run a command outside its allowlist:
bun ah -p openclaw -m "run command: grep timeout data/logs/demo.log"If the command isn't on the fixed allowlist, the harness prioritizes legibility by stopping and surfacing a refusal:
Reply: Command policy result for "grep timeout data/logs/demo.log":
Policy: needs_approval
Reason: Command is outside the OpenClaw demo allowlist.
Permission Decisions
! openclaw:grep timeout data/logs/demo.log -> needs_approval (Command is outside the OpenClaw demo allowlist.)
Model Decisions
? Dispatching run_command for "grep timeout data/logs/demo.log".
? Tool results detected (run_command) composing final response.Now ask Hermes to read a host file:
bun ah -p hermes -m "run command: cat /etc/hosts"Instead of Hermes saying that the verb is disallowed, it routes through a sandbox and lets the sandbox boundary decide:
Reply: Command policy result for "cat /etc/hosts":
Policy: sandboxed
Reason: Hermes runs this through the demo sandbox policy.
Output:
Operation not permitted: /etc/hosts
Permission Decisions
! hermes:cat /etc/hosts -> sandboxed (Hermes runs this through the demo sandbox policy.)
Sandbox Events
# Synced Hermes sandbox fixtures into ./data/sandboxes/hermes.
Model Decisions
? Dispatching run_command for "cat /etc/hosts".
? Tool results detected (run_command) composing final response.Since /etc/hosts escapes the workspace boundary, the operation is not permitted and fails.
State and Artifacts
Our final category of comparison examines what survives a turn beyond the reply.
OpenClaw's state is sparse and visible.
bun ah -p openclaw -u alice -s prefs -m "Remember that I prefer zsh for shell work"When memory is saved explicitly, there's a Memory Writes line:
Reply: Saved explicit memory: I prefer zsh for shell work.
Memory Writes
+ Saved explicit memory: I prefer zsh for shell workA single explicit request triggers a single write and recall path.
Hermes leaves behind multiple artifacts from a single turn:
bun ah -p hermes -u alice -s logs -m "search recent logs for timeout failures"The artifacts can include learned user facts, reusable skill notes, and sandboxed report artifacts:
Generated Skills
* ./data/skills/search-recent-logs-for-timeout-failures.md
Sandbox Events
# Synced Hermes sandbox fixtures into ./data/sandboxes/hermes.
# Wrote sandbox report ./data/sandboxes/hermes/reports/timeout-failures.txt.OpenClaw keeps writes minimal and explicit whereas Hermes treats state accumulation as a core feature.
Where Agents Are Going Next
The harness decisions compared in this article (what to remember, automate, allow, and preserve) are locked into the agent's code. Current lines of work seek to expand the range of agent behavior to give it control over these aspects as well.
HyperAgents (Zhang et al., March 2026) introduces agents that can rewrite their task-solving logic and improvement mechanism. This enables the agents to autonomously develop capabilities like persistent memory and performance tracking which compound across multiple runs.
Karpathy's AutoResearch (March 2026) applies the same propose-execute-evaluate loop to the domain of machine learning research. A minimal script gives an agent a training setup and plain-English strategy file (program.md). The agent experiments by modifying code and training for five-minute intervals. It keeps the winners, discards the losers, and repeats indefinitely.
MemSkill (Zhang et al., February 2026) specifically targets the memory axis by reframing static operations like save and search as learnable, modifiable skills. A controller selects the skills and a designer periodically refines and evolves them based on failure cases.
These projects point towards a future where the choices we compared manually (passive versus proactive memory, direct versus staged tool paths, explicit versus automatic state) become a search and design space that the agents navigate themselves and refine through self-improvement.
Conclusion
Even though both agents share the same outer loop and answer the same prompts through the same interface, the difference is seen in the defaults. OpenClaw bets on explicit memory control, direct tool paths, allowlist gating, and minimal writes. Hermes bets on assembled context, heavier workflow orchestration, sandbox confinement for workspaces, and automatic state accumulation.
When evaluating an agent, run the same prompt through the same CLI surface and inspect what the harness reveals. What does the harness assemble, what path does it take, what policies govern its execution, and what does it leave behind? The shared loop does little because the wrapper is where the system decides what to remember, what to automate, what to allow, and what to preserve.
References
- system-and-signal: companion repo for the shared-loop CLI comparison
- OpenClaw: local-first personal AI assistant with channels, voice, and canvas
- OpenClaw Memory docs: file-backed memory model and memory plugins
- OpenClaw Tools docs: first-class tools for browser, canvas, nodes, and cron
- OpenClaw default AGENTS.md: default workspace/identity guidance for agent behavior
- Hermes Agent docs: self-improving agent platform with memory, skills, and multi-environment execution
- Hermes Agent GitHub README: overview of persistent memory, skill creation, toolsets, and container isolation
- OpenAI Responses API: shared model/tool-calling backend relevant to the common loop framing
- SQLite FTS5: full-text search extension relevant to Hermes session recall and search behavior